
Playwright安装及常用函数
发展
selenium->cypress、puppeteer、testcafe->playwright
Get Started
Installation | Playwright Python
我用的conda
1 | conda create -n env4pr |
创建测试文件test_example.py
1 | import re |
然后在文件夹下cmd中
1 | pytest |
2 passed in 2.64s 成功
问题
- playwright install时,以为报错了,结果没有,可以看到有两个文件,下载第一个尝试链接失败,第二个成功
1 |
|
2.又报错
1 |
|
网络问题,懂的都懂
Playwright的几种写法
- 1 先自动生成,后修改
- 2 异步和同步写法
- 3 test和非test写法
Feature:
playwright的特点:无需等待,无需解决竞争冲突
写测试:导航-定位-操作-断言
步骤:
1导航到页面
1 | page.goto(<url>) |
2交互:定位元素、操作元素
Playwright使用Locator API定位元素,没必要等待因为会自动等待定位的元素为可操作条件再执行后续操作
1 | # 定位元素,返回的get_started是一个Locator对象 |
允许的操作方法Action(locator的Action)
| Action | Description |
|---|---|
| locator.check() | Check the input checkbox |
| locator.click() | Click the element |
| locator.uncheck() | Uncheck the input checkbox |
| locator.hover() | Hover mouse over the element |
| locator.fill() | Fill the form field, input text |
| locator.focus() | Focus the element |
| locator.press() | Press single key |
| locator.set_input_files() | Pick files to upload |
| locator.select_option() | Select option in the drop down |
断言以实现等待
Playwright使用断言来等待元素满足期待的条件(之后可操作),从而让它变得稳定可靠。比如
1 | import re |
几种断言方法
| Assertion | Description |
|---|---|
| expect(locator).to_be_checked() | Checkbox is checked |
| expect(locator).to_be_enabled() | Control is enabled |
| expect(locator).to_be_visible() | Element is visible |
| expect(locator).to_contain_text() | Element contains text |
| expect(locator).to_have_attribute() | Element has attribute |
| expect(locator).to_have_count() | List of elements has given length |
| expect(locator).to_have_text() | Element matches text |
| expect(locator).to_have_value() | Input element has value |
| expect(page).to_have_title() | Page has title |
| expect(page).to_have_url() | Page has URL |
fixtures
它是pytest的一个特性,类似装饰器,在调用一个测试前后可以做些事,暂不深究
https://docs.pytest.org/en/6.2.x/fixture.html#autouse-fixtures-fixtures-you-don-t-have-to-request
异步和同步写法
异步代码一般前面需要加一个await,定义函数和打开文件需要加上async;import时调用的东西也不一样。
1 | # 异步 |
1 | # 同步 |
由于某些原因,以上代码没法在jupyter notebook中成功运行,此外还有别的问题
非test写法
上面两个都是非test的写法
模板
模板包括 异步/同步+test/非test模板,目前有三个,如上2和下1
1 | from playwright.sync_api import Page, expect |
问题:如何定位元素?
1.使用Codegen自动生成(可能不对,需要修改)
2.去Locators | Playwright Python自己写代码
CodeGen
会生成两个窗口,一个是test窗口,一个是监视窗口,可以用来记录、复制、清楚测试并改变测试语言。
使用codegen命令来运行测试生成器,URL可以跟在codegen之后或者也可以直接输入
1 | playwright codegen demo.playwright.dev/todomvc |
运行codegen,在浏览器执行操作。Playwright将根据用户交互生成代码。“Codegen”将查看呈现的页面,生成推荐的定位器,对role, text 和test id定位器进行优先级排序。如果生成器识别出与定位器匹配的多个元素,它将改进定位器,使其具有弹性并唯一地识别目标元素,从而消除和减少由于定位器导致的测试失败和剥落。
完成与页面的交互后,按“录制”按钮停止录制,并使用“复制”按钮将生成的代码复制到编辑器中。
使用“清除”按钮清除代码以重新开始录制。完成后,关闭Playwright检查器窗口或停止终端命令。
要了解有关生成测试的更多信息,请查看Codegen上的详细指南。
https://playwright.dev/python/docs/codegen
模仿
模拟地理位置、语言、时区、设备、特点视角、配色,保存验证的身份信息。查看测试生成器指南以了解更多信息。
1.模仿窗口大小
1 | playwright codegen --viewport-size=800,600 playwright.dev |
2.模仿设备
1 | playwright codegen --device="iPhone 13" playwright.dev |
类似的,模仿配色、地理位置、语言、时区、
–color-scheme=dark
1 | playwright codegen --timezone="Europe/Rome" --geolocation="41.890221,12.492348" --lang="it-IT" bing.com/maps |
3.登录、cookies等
–save-storage=auth.json:保存cookies和存储信息
–load-storage=auth.json:加载cookies和存储信息,用于登录!!!
1 | playwright codegen <url> --load-storage=auth.json |
元素定位-Locator
定位方法大致可以分为自带方法、XPath方法、CSS方法和混合方法
playwright自带定位方法
- page.get_by_role() to locate by explicit and implicit accessibility attributes.
- page.get_by_text() to locate by text content.
- page.get_by_label() to locate a form control by associated label’s text.
- page.get_by_placeholder() to locate an input by placeholder.
- page.get_by_alt_text() to locate an element, usually image, by its text alternative.
- page.get_by_title() to locate an element by its title attribute.
- page.get_by_test_id() to locate an element based on its data-testid attribute (other attributes can be configured).
XPath方法
XPath 是一门在 XML 文档中利用“节点树路径”查找信息的语言,XPath即为XML路径语言(XML Path Language),XQuery 和 XPointer 均构建于 XPath 表达式之上
在开发者工具中复制
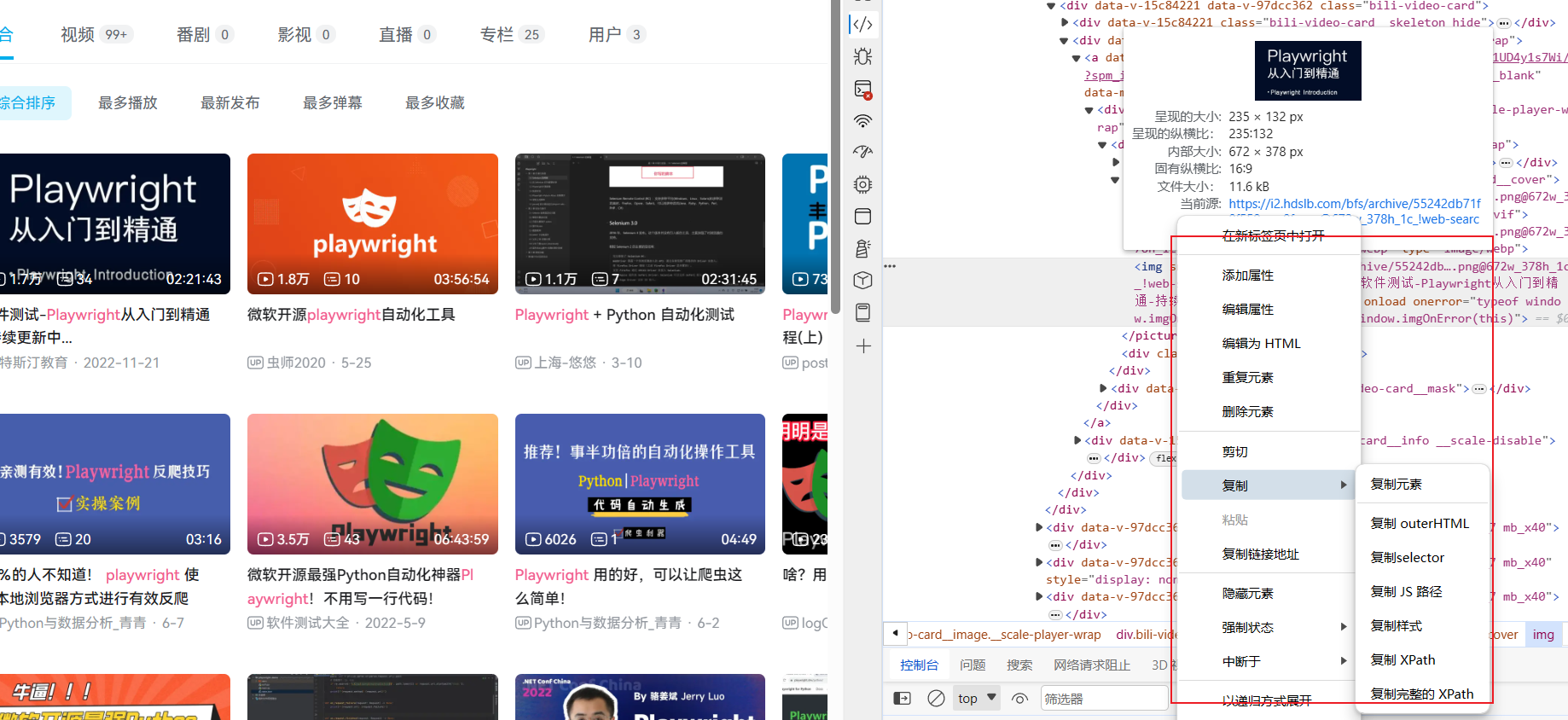
开发者工具可以使用定位器找到网页某个位置对应元素,然后复制选项中有XPath
节点关系
- 父(Parent)
- 子(Children)
- 兄弟节点(同胞(Sibling))
- 先辈(Ancestor):所有上级
- 后代(Descendant):所有下级
1 | <bookstore> |
book的父节点是bookstore,子节点是title、author、year和price,它们互为兄弟节点,book和title都是bookstore后代,book和bookstore都是title的先辈
展开查看
被你发现了!Markdown中实现内容折叠操作!
相对和绝对路径
绝对://*[@id=”i_cecream”]/div[2]/div[1]/div[1]/ul[1]/li[6]/a/span
相对:
xpath绝对路径用单斜线“/”表示,xpath 相对路径用双斜线“//”表示,“/”:元素是上一级节点的子节点。“//”:子孙节点
推荐使用相对路径,防止中间路径改变导致不可用
XPath唯一性和准确性的检查和debug
- 可以在浏览器开发者工具-console控制台 输入:
1
$x('<XPath>')
- 直接在元素中用XPath表达式搜索
执行后将返回匹配到的xml元素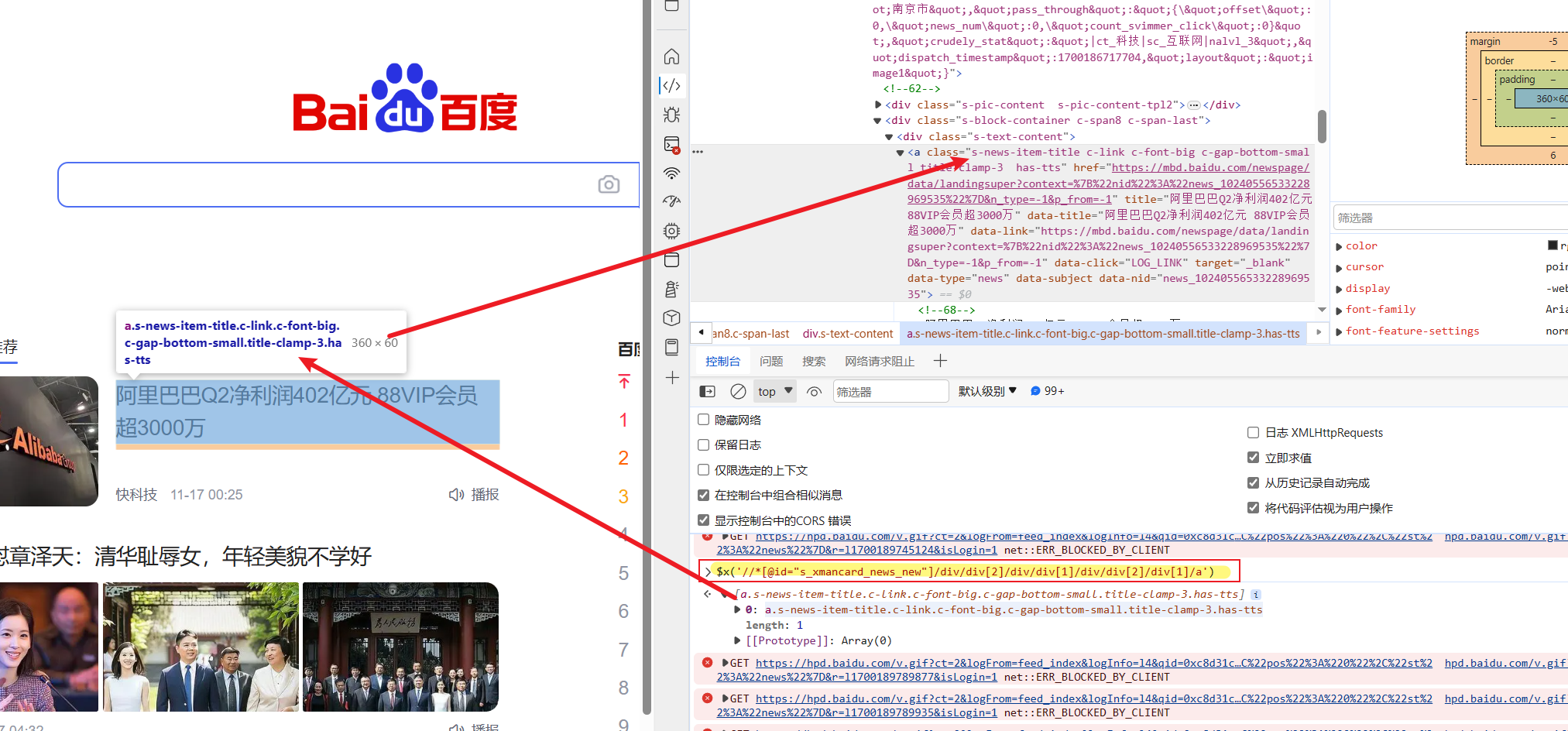
如果匹配到的元素过多,可以增加限制”and”;否则,若匹配不到,要么路径错误要么需要更灵活一点
一些案例
1 | #单一属性定位,下面定位<span>标签的name为tj_settingicon的元素 |
1 | #通过父节点定位子节点,定位<div>标签Qid为u1的子节点/span |
注意:列表索引是从1开始,而不是0开始;每个索引的1是从父节点计数的,也就是说每个父节点都是不一样的列表
我们用id定位a标签,得到了十个热搜列表,其实XPath写法很简单,像url/path和html代码的混合:
//<标签类>[@属性=”xxxx”],属性等于甚至可以从html中复制,如果还要相对路径或者索引,就加/和[数字]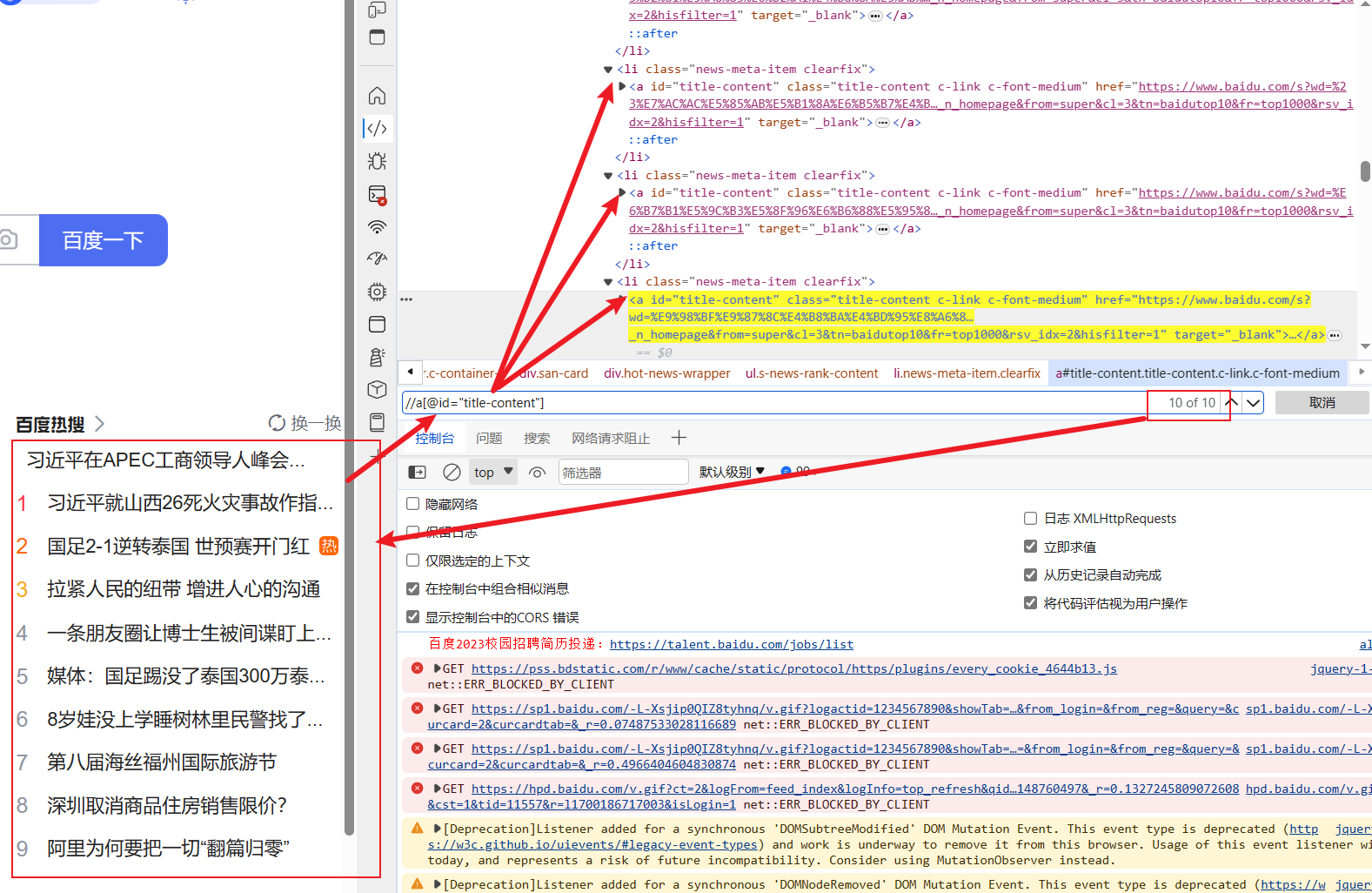
图片的定位
一种XPath定位方法://*[img]或者//img
图片标签<img>的属性有src、alt、title、width、height、boarder等
CSS定位
截图
全页、看到的页面、元素的截图
1 | # full screen |
录屏
见-错误
下载
html源码及文本内容
- page.content() 返回所有html源码
返回locator定位到的元素的文本/源码:
- locator.inner_html()源码
- locator.inner_text()文本
- locator.text_content()文本
包括子元素和隐藏元素,inner会格式化文本,且依赖于显示的CSS代码??
列表形式:
- locator.all_inner texts()
- locator.all_text_contents()
页面切换
早就想问页面切换的问题了,恰好碰到了讲解的网页,整理一下refrence
只需要创建上下文,然后遍历它的context.pages即可
1 | #遍历page对象 |
作者还写了一个根据title或url选择标签页的函数:
1 | def switch_to_page(context,title=None,url=None): |
selenium进行web自动化测试,如果我们打开了多个网页,进行网页切换时,我们需要先获取各个页面的句柄,通过句柄来区分各个页面,然后使用switch_to.window实现切换,这样的操作比较麻烦
js代码执行
网络请求日志
Cookies保存和加载
通常我们期望手动在浏览器或新开的浏览器GUI保存cookies,而不是写代码找到输入框输入密码账号过验证码再保存cookies;
在写代码时候,自动加载cookies。
cookies的保存
法1.使用codegen保存cookies,在打开的界面登录:
1 | code url --save-storage=path_to_cookies.json |
法2.使用软件cookies editor保存domain ,name,path,value,配合加载 法2
法3.代码,配合加载法1
关于context,类似于page的父,一个context管很多的page,不同的context不share cookies/cache
1 | import json |
cookies的加载
法1:
1 | # Load the cookies |
法2:下面代码需要手动输入cookies
1 | cookies = [] |
完整test示例
1 | from playwright.sync_api import sync_playwright |
other
其它问题
1 playwright找不到,原因是未激活conda env4pr环境
2 有的翻页链接不是序号,而是一串网址,需要匹配提取后再传入get的url参数,request后再提取
1 | <nav aria-label="Page navigation"> |
有五页,分别在href中
1 | # 请求原网页 |
ref:
https://blog.51cto.com/SpiderBy/p_2
反爬
goto 反爬专栏,因为攻防互易原因不一定放出来
排错
1.Error: strict mode violation: locator(“xpath=XXXX”) resolved to 10 elements:
locator是严格模式,只能定位最多一个元素,参考Locators strictness,只能使用.first/.last/.nth+.count来选择元素
2.expect(page.query_selector_all(‘xpath=//h3/a’)).to_be_visible()报错
expect to_be_visible 可以最多expect一个元素,改为page.wait_for_selector
遗憾的是locator没有支持多个匹配的方法。
3.test中暂时没有打印输出,playwright未开发
4.playwright._impl._api_types.Error: Page is not yet closed. Close the page prior to calling save_as
先关了网页才能结束录制和保存视频,下面是另一错误
1 | page.video.save_as('./test/test_screen_record/video/1.mp4') |
playwright._impl._api_types.Error: Page closed,page已经关了,没法保存
解决方法:在开启page的时候,添加record_video_dir参数
1 | page = browser.new_page( |
默认保存格式为webm,如果要保存,那么一定要在context关闭之后再保存
1 | context.close() |
缺点:清晰度非常低,改进方法:在page构造加入参数,增大录制大小和窗口大小
1 | record_video_size={"width": 1920, "height": 1080}, |
viewport一般和设备有关,有默认viewport,设置了适合于设备的窗口大小之类的。
Playwright命令行
1 | playwright |