
Spark
[[Spark 的基本数据模型]]
Application由多个Job组成,Job由多个Stage组成,Stage由多个Task组成。Stage是作业调度的基本单位。
RDD:是弹性分布式数据集(Resilient Distributed Dataset)的简称,是分布式内存的一个抽象概念,提供了一种高度受限的共享内存模型。
DAG:反映RDD之间的依赖关系。
Driver Program:控制程序,负责为Application构建DAG图。
Cluster Manager:集群资源管理中心,负责分配计算资源。
Worker Node:工作节点,负责完成具体计算。
Executor:是运行在工作节点(Worker Node)上的一个进程,负责运行Task,并为应用程序存储数据。
Application:用户编写的Spark应用程序,一个Application包含多个Job。
Job:作业,一个Job包含多个RDD及作用于相应RDD上的各种操作。
Stage:阶段,是作业的基本调度单位,一个作业会分为多组任务,每组任务被称为“阶段”。
Task:任务,运行在Executor上的工作单元,是Executor中的一个线程。
架构
Spark集群由Driver, Cluster Manager(Standalone,Yarn 或 Mesos),以及Worker Node组成。对于每个Spark应用程序,Worker Node上存在一个Executor进程,Executor进程中包括多个Task线程。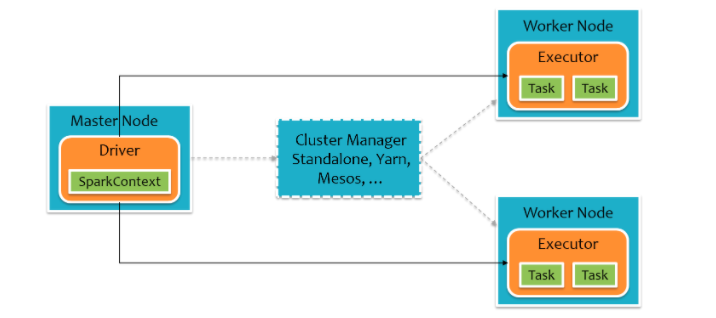
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 Min的博客!
评论