
Clickhouse使用和学习
Clickhouse

Clickhouse
阿里云、思科、滴滴、IBM、LangChain、索尼、Cloudflare、eBay、DeepL、百度都用它
Clickhouse 有中文文档,但是不全;读完全部的Docs和SQL Reference基本上用起来没有任何问题了,而且它还有自带的AI
Clickhouse存储数据所支持的数据类型
- Integer types: signed and unsigned integers (
UInt8,UInt16,UInt32,UInt64,UInt128,UInt256,Int8,Int16,Int32,Int64,Int128,Int256) - Floating-point numbers: floats(
Float32andFloat64) andDecimalvalues - Boolean: ClickHouse has a
Booleantype - Strings:
StringandFixedString - Dates: use
DateandDate32for days, andDateTimeandDateTime64for instances in time - JSON: the
JSONobject stores a JSON document in a single column - UUID: a performant option for storing
UUIDvalues - Low cardinality types: use an
Enumwhen you have a handful of unique values, or useLowCardinalitywhen you have up to 10,000 unique values of a column - Arrays: any column can be defined as an
Arrayof values - Maps: use
Mapfor storing key/value pairs - Aggregation function types: use
SimpleAggregateFunctionandAggregateFunctionfor storing the intermediate status of aggregate function results - Nested data structures: A
Nesteddata structure is like a table inside a cell - Tuples: A
Tupleof elements, each having an individual type. - Nullable:
Nullableallows you to store a value asNULLwhen a value is “missing” (instead of the column settings its default value for the data type) - IP addresses: use
IPv4andIPv6to efficiently store IP addresses - Geo types: for geographical data, including
Point,Ring,PolygonandMultiPolygon - Special data types: including
Expression,Set,NothingandInterval
Epoch纪元
Date VS Date32 日期
Date为1970至今,Date32可以记录1970年以前,用int32有符号数,0表示1970
DateTime VS DateTime64 日期+时间
datetime是秒级,datetime64为秒级以下,构造如下DateTime64(precision, [timezone]),即包含精度位数和时区,Tick size (precision): 10-precision seconds. Valid range: [ 0 : 9 ]. 比如 3 (ms), 6 (us), 9 (ns).最大支持的精度为8
表示的时间范围为[1900-01-01 00:00:00, 2299-12-31 23:59:59.99999999]
ClickHouse使用方法和逻辑
ClickHouse将数据仓库分为很多个数据库,每个数据库包含很多表,建立数据库的方法如下:
1 | CREATE DATABASE IF NOT EXISTS helloworld |
上述语句创建了一个helloworld数据库
建表的方法如下
1 | CREATE TABLE helloworld.my_first_table |
上述语句在helloworld创建了my_first_table表,TABLE/DATABASE说明是建表/库,第二到第七行指定了Scheme,用到了UInt32\String\DateTime\Float32数据类型,引擎是MergeTree, Primary key是 (user_id, timestamp)
Primary key 主键
对于同一个表的每一行,主键并不唯一
主键决定了表写入磁盘的数据顺序.每8192行或10MB(索引粒度)数据会在主键索引文件中创建一个入口,这样的粒度保证了稀疏索引能够轻松放入内存.索引粒度表示了被SELECT语句查询和处理的最小列数据的粒度
主键可以用 PRIMARY KEY或ORDER BY设置,如果都有,那么主键是order的子集
主键也是排序键,以上表为例,每一列文件会按照user_id排序,然后按照timestamp排序
数据插入
1 | INSERT INTO helloworld.my_first_table (user_id, message, timestamp, metric) VALUES |
数据查看
1 | SELECT * FROM helloworld.my_first_table |
作为OLAP数据库,ClickHouse针对高性能和可伸缩性进行了优化,每秒可以插入数百万行。这是通过高度并行化的体系结构、从列方向上的高压缩以及在一致性上的妥协来实现的。更具体地说,ClickHouse针对仅追加操作进行了优化,只提供最终一致性保证。
相比之下,OLTP数据库(如Postgres)专门针对事务性插入进行了优化,具有完全的ACID遵从性,确保了强一致性和可靠性保证。PostgreSQL使用MVCC(多版本并发控制)来处理并发事务,这涉及到维护多个版本的数据。这些事务一次可能只有少量行,由于可靠性保证限制了插入性能,因此会产生相当大的开销。
为了在获得强一致性保证的同时获得高插入性能,用户在插入ClickHouse时应该遵循以下简单规则。这也避免了用户在第一次使用ClickHouse和复制OLTP插入策略时遇到的常见问题。
数据插入的最佳实践
大批量插入
减少写入次数:默认情况下,发送给ClickHouse的每次插入操作会立即创建一个包含插入数据及必要元数据的存储部分。因此,相比发送大量包含较少数据的插入请求,发送较少但每批次包含更多数据的插入请求可以减少所需的写入次数。通常建议至少一次插入1,000行数据,理想情况下,每次插入应在10,000至100,000行之间。详情请参阅相关文档。
确保一致的批次以支持幂等重试
幂等性与重试:默认情况下,向ClickHouse的插入操作是同步的,并且如果完全相同则具有幂等性。对于MergeTree引擎系列的表,ClickHouse会自动去重插入的数据。这意味着在以下情况下插入操作是容错的:
如果接收数据的节点出现问题,插入查询将超时(或收到更具体的错误),而不会收到确认。
即使数据已被节点写入,但由于网络中断无法返回确认给发送方,发送方要么收到超时,要么收到网络错误。
从客户端的角度来看,这两种情况很难区分。但是,在两种情况下,未得到确认的插入都可以立即重试。只要重试的插入查询包含相同顺序的相同数据,如果原始(未得到确认)插入成功,ClickHouse将自动忽略重试的插入。
插入到MergeTree或Distributed表
直接插入MergeTree表:我们建议直接插入到MergeTree(或Replicated表),如果数据被分片,则在一组节点间平衡请求,并使用internal_replication=true。这将让ClickHouse负责将数据复制到任何副本分片,并确保数据最终一致。如果客户端负载均衡不便,用户可以通过Distributed表插入。这将分布写入跨节点(同样,保持internal_replication=true)。这种方法性能略低,因为写入操作必须首先在带有Distributed表的节点上本地进行,然后再发送到分片。
对于小批量使用异步插入
异步插入:在某些场景下,客户端批量处理不可行,例如,观测性用例中有数百或数千个专用代理发送日志、指标、跟踪等,其中实时传输数据是关键,以便尽快检测问题和异常。此外,被观测系统中事件峰值的风险可能导致尝试在客户端缓冲观测数据时出现大的内存峰值和相关问题。如果不能插入大数据量的批次,用户可以使用异步插入将批量处理委托给ClickHouse。通过异步插入,数据首先插入到缓冲区,然后稍后或异步地写入数据库存储。
With enabled asynchronous inserts, when ClickHouse (1) receives an insert query, then the query’s data is (2) immediately written into an in-memory buffer first. Asynchronously to (1), only when (3) the next buffer flush takes place is the buffer’s data sorted and written as a part to the database storage. Note that the data is not searchable by queries before being flushed to the database storage; the buffer flush is configurable.
Before the buffer gets flushed, the data of other asynchronous insert queries from the same or other clients can be collected in the buffer. The part created from the buffer flush will potentially contain the data from several asynchronous insert queries. Generally, these mechanics shift the batching of data from the client side to the server side (ClickHouse instance).
Full details on configuring asynchronous inserts can be found here, with a deep dive here.
Use official clients - ClickHouse has clients in the most popular programming languages. These are optimized for ensuring inserts are performed correctly and natively support asynchronous inserts either directly e.g. in the Go client, or indirectly when enabled in the query, user or connection level settings.
Native format preferred - ClickHouse supports many input formats at insert (and query) time. This is a significant difference with OLTP databases and makes loading data from external sources much easier - especially when coupled with table functions and the ability to load data from files on disk. These formats are ideal for ad hoc data loading and data engineering tasks. For applications looking to achieve optimal insert performance, users should insert using the Native format. This is supported by most clients (Go and Python) and ensures the server has to do minimal work since this format is already column-oriented. This thus forces the work to produce column-oriented data for the client, which should be considered in any effort to scale inserts. Alternatively, users can use RowBinary format (as used by the Java client) if a row format is preferred - this is typically easier to write than the native format. This is more efficient, in terms of compression, network overhead, and processing on the server, than alternative row formats such as JSON. JSONEachRow format can be considered for users with lower write throughputs looking to integrate quickly. Users should be aware this format will incur a CPU overhead in ClickHouse for parsing.
HTTP or Native protocol - Unlike many traditional databases, ClickHouse supports an HTTP interface. Users can use this for both inserting and querying data, using any of the above formats. This is often preferable to ClickHouse’s native protocol as it allows traffic to be easily switched with load balancers. We expect small differences in insert performance with the native protocol, which incurs a little less overhead. Existing clients use either of these protocols ( in some cases both e.g. the Go client). The native protocol does allow query progress to be easily tracked.
查询:
查询语句,SQL语法 :
1 | SELECT * |
FORMAT可以省略,默认为好看的table,Clickhouse支持多种多样的返回格式
ClickHouse 支持超过 70 种输入和输出数据格式,这使得它能够在不同的数据源和目标之间进行灵活的数据交换。这些格式包括但不限于 CSV、JSON、XML、Parquet、ORC、MsgPack、Protobuf。这种广泛的格式支持意味着 ClickHouse 可以轻松地读取和写入各种数据源,无论是从文件系统、云存储还是其他数据库。
此外,ClickHouse 提供了数千种内置函数,涵盖了数学、字符串操作、日期和时间处理、数组操作、JSON处理等多个领域。这些函数可以用来进行复杂的数据清洗、格式化、聚合和其他数据转换任务,而无需编写大量的自定义代码。
即使没有一个正在运行的 ClickHouse 服务器,你也可以利用
clickhouse-local工具进行数据转换。clickhouse-local是 ClickHouse 的一个命令行工具,它可以独立于 ClickHouse服务运行,直接在本地机器上执行 SQL 查询。这意味着你可以在没有设置完整数据库环境的情况下进行数据预处理、测试查询或进行小规模的数据转换。
TTL
TTL(生存时间)是指在一定的时间间隔过后移动、删除或卷起行或列rollup的能力。TTL有几个作用:
- 删除: 删除旧数据
- 移动:经过一定的时间后,您可以在存储卷之间移动数据——这对于部署热/暖/- 冷架构非常有用 数据汇总:
- 上卷:在删除旧数据之前,将旧数据汇总到各种有用的聚合和计算中,比如只记录一个月的总收入而非每天的收入
TTL语句可以出现在一列或一个表定义的后面,使用INTERVAL定义时长,需要是Date or DateTime类型。比如,下表有两列定义了TTL
1 | CREATE TABLE example1 ( |
ClickHouse会将过期的列值替换为默认值,如果所有列值都过期了,就会在文件系统删除列这里TTL中的timestamp 是列名
TTL事件的触发
The deleting or aggregating of expired rows is not immediate - it only occurs during table merges. If you have a table that’s not actively merging (for whatever reason), there are two settings that trigger TTL events:
TTL事件(过期行的删除和聚合)不是立即发生的,仅当 并表 时发生。 如果合并不积极,可以有两种方法触发TTL事件:
- merge_with_ttl_timeout
- merge_with_recompression_ttl_timeout
行移除
1 | CREATE TABLE customers ( |
12小时会TTL
暖/温/冷架构
在TTL中使用TO DISK 和 TO VOLUME语句来实现暖/温/冷架构(不一定是暖/温/冷——无论为了什么目的,都可以使用TTL来移动数据。)
将配置文件my_system.xml放入/etc/clickhouse-server/config.d/来使配置生效,在配置文件中定义存储和硬盘来让TO DISK 和 TO VOLUME语句指定存放的位置。
1 | <clickhouse> |
前半段指定了hot_disk、warm_disk、cold_disk的位置分别为./hot/,./warm/,./cold/,后半段指定了default volume为default,hot_volume为hot_disk,warm_volume:warm_disk,cold_volume:cold_disk,可以通过如下方式查询
1 | SELECT name, path, free_space, total_space |
下面进行确认
1 | SELECT |
之后,设定TTL规则实现暖/温/冷架构
1 | ALTER TABLE my_table |
去重策略(略,无需)
Clickhouse在放数据前不会检查数据是否重复,去重是事件驱动的,并且有副作用
表引擎
分类:
——-合并树家族
——-日志家族
——-集成外部(外部数据库作为表引擎)
——-特殊表引擎
内存引擎是用于测试\少量数据的高速引擎,生产中基本不会使用,属于特殊表引擎.
合并树
合并树用于高速写入和大量数据存储,写入操作创建了部分表,由一个后台进程处理合并这些”部分表”的合并.合并表的特点:
- 主键决定了表的部分的顺序,主键索引的是粒度,即很多行,从而使得主键变少,并加速硬盘数据访问
- 表可以被分区,利用分区剪枝优化查询
- 不会去重,但是replacingMergeTree只会保留重复内容的最新版本
ORDER BY和Primary key的设置
ORDER BY 子句在 ClickHouse 中用于指定数据的物理排序规则。它决定了数据在磁盘上的布局和排序方式,这直接影响到查询的效率。而 Primary key定义了逻辑顺序,即检索的生成.
每个表只有一个 ORDER BY和一个Primary key,但是它们都可以包含多列
Primary key是 ORDER BY的子集,且必须从头开始,不能包含了ORDER by后面的却不包含更优先的.例如: 如果 ORDER BY 是 (column1, column2, column3),则 PRIMARY KEY 可以是:
1 | PRIMARY KEY (column1) |
或
1 | PRIMARY KEY (column1, column2) |
但不能是:
1 | 1PRIMARY KEY (column2) |
数据写入过程中的合并
数据分片:当数据写入到 ClickHouse 的 MergeTree 表中时,数据会被分割成多个较小的数据块(也称为 “part” 或 “chunk”)。每个数据块通常包含连续的行,按照
ORDER BY列进行排序。合并操作:随着时间推移,同一分区内的多个数据块可能会形成。为了保持数据的有序性和减少冗余,ClickHouse 的后台进程会定期合并(merge)这些数据块,生成一个更大、更优的数据块,该数据块具有更好的压缩率和查询性能。合并过程中,数据会被重新排序和压缩。
查询过程中的合并
分区剪枝:在执行查询时,ClickHouse 会利用分区信息(如果有的话)来剪枝(prune)无关的分区,只读取与查询条件相匹配的分区数据。
数据块合并:即使在查询时,ClickHouse 也可能需要从多个数据块中读取数据。为了提供一致的查询结果,它会合并这些数据块中的数据,按照
ORDER BY列进行排序,然后应用过滤和其他查询操作。
树状结构
MergeTree 的名称也暗示了数据在物理存储上的树状结构。每个分区可以看作是一个树的根节点,下面分支出多个数据块(叶子节点)。随着合并操作的发生,这些叶子节点会逐渐向上合并,形成树的中间节点,最终趋向于单一大数据块的理想状态。
综上所述
MergeTree 的命名反映了 ClickHouse 在处理数据时的核心机制——不断进行数据的合并操作,以维持数据的高效存储和快速查询能力。这种设计确保了即使是面对大量数据的持续写入,ClickHouse 也能保持良好的性能和资源利用率。
分区剪枝(Partition Pruning)
分区剪枝是 ClickHouse 在执行查询时的一种优化技术。当一个查询被执行时,ClickHouse 会分析查询条件,判断哪些分区的数据实际上对查询结果没有贡献。基于此分析,ClickHouse 可以决定忽略那些无关的分区,只读取真正需要的数据分区。这种技术显著减少了查询所需扫描的数据量,从而大大加快了查询速度。
例如,假设你有一个基于日期分区的表,并执行一个查询,该查询只请求去年某个特定月份的数据。在这种情况下,ClickHouse 可以通过分区剪枝技术排除所有不属于去年该特定月份的分区,只扫描相关的数据,从而避免了不必要的磁盘I/O操作和CPU计算。
分区剪枝的效率主要依赖于查询条件与分区键的匹配程度。如果查询条件能紧密对应分区键,则分区剪枝的效果会更好。因此,在设计 ClickHouse 表时,合理选择分区键是至关重要的,以确保查询能够最大化利用分区剪枝带来的性能提升。
内存引擎
展望:ChDB
ChDB是一款in-process db(嵌入式数据库),能避免网络带来的延迟,并且能够使用MemoryView在C++和python间跨语言传输数据.
硬盘估算
57.65 M 数据 1.6G pcap
35.4M/G*1G/s*0.7~2 = 30~70M/s =4.2G/min = 252G/h
200G能撑:
200G/70M/60s/min = 47.6min
如果要保存3小时的全包,需要300-756G,取决于包大小和数量
查看表大小:
1 | SELECT formatReadableSize(sum(data_compressed_bytes)) AS table_size |
状态监控:
URL: $HOST:$PORT/dashboard
1 | SELECT hashVal, groupArray(id) AS id_list FROM default.numbers WHERE datetime >= now() - INTERVAL 1 SECOND GROUP BY hashVal; |
Clickhouse Cpp
1.clickhouse-cpp
Clickhouse Cpp的客户端不是线程安全的
⚠ Please note that Client instance is NOT thread-safe. I.e. you must create a separate Client for each thread or utilize some synchronization techniques. ⚠
Clickhouse Cpp没有实现错误重试的逻辑
If you wish to implement some retry logic atop of clickhouse::Client there are few simple rules to make you life easier:
- If previous attempt threw an exception, then make sure to call
clickhouse::Client::ResetConnection()before the next try. - For
clickhouse::Client::Insert()you can reuse a block from previous try, no need to rebuild it from scratch.
2.userver
我没有使用userver
debug:can’t receive string data: Connection reset by peer
经过lsof -i等排查,发现Clickhouse-Cpp编译出的程序在使用端口被ipykernel占用,kill掉
1 | ./application-example |
Clickhouse内置函数
你想要的基本都有,基本的类型操作,甚至包括简单传统NLP算法,也能生成UUID,生成range和one等序列,例如:
has: 1 in arr
hasany [1,2] any in arr
hasall: [1,2] all in arr:各类距离:Lp norm,…
UDF:支持python自定义函数
视图
创建一个新视图,视图可以是普通视图、物化视图、实时视图和窗口视图(实时视图和窗口视图是实验性的功能)。
普通视图
普通视图只不过是保存的查询。当从视图中读取时,这个保存的查询被用作from子句中的子查询。
1 | CREATE [OR REPLACE] VIEW [IF NOT EXISTS] [db.]table_name [ON CLUSTER cluster_name] |
含参视图
类似于普通视图,不过带有参数,可以动态传参,类似于一个带参的表函数,输入为表,计算出另一个表
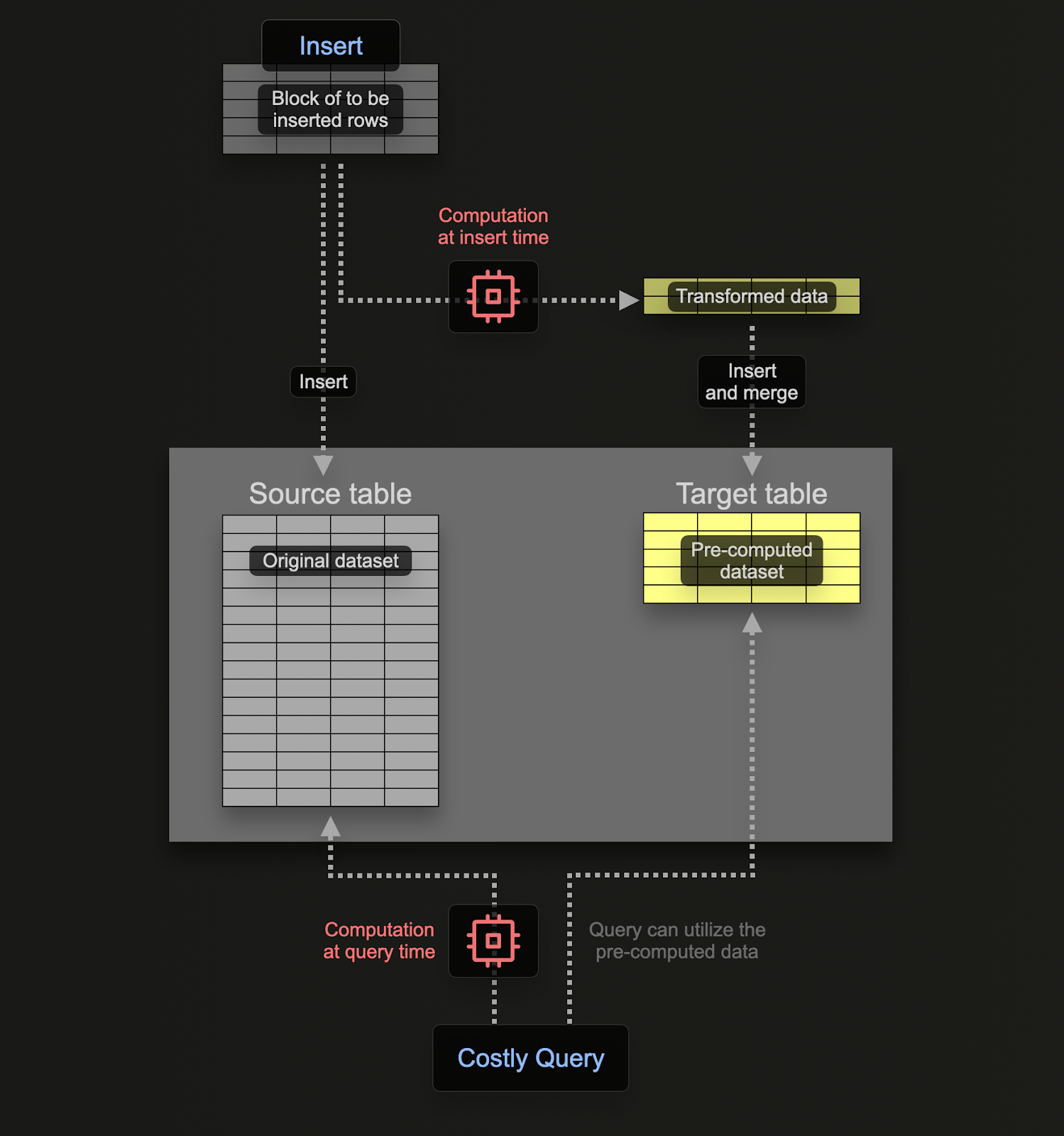
Materialized View 物化视图
物化视图用插入开销换取检索开销,使得检索更快.
与事务数据库如Prostgres不同,CLickhouse的物化视图是一个在数据块插入表格时执行检索的触发器.检索的结果被插入为第二目标表,如果插入更多行,结果将再次发送到目标表,中间结果将被更新和合并。合并的结果等价于对整个表执行检索.
物化视图的动机是插入目标表格的结果 表示 聚合\过滤\行变换的结果. 这些结果通常是原始数据的更小表示.用物化视图直接获取结果代替检索时执行聚合\过滤\行变换的结果,简单而快捷,用插入开销换取检索开销.
物化视图是实时进行的,伴随数据流入的过程,如同持续更新索引一样.与之相反,其它数据库中的物化视图只是静态快照,必须要更新(Clickhouse相同的东西叫 refreshable materialized views)
实时视图live(废除)
窗口视图
时间窗函数:给定时间起点和间隔,返回区间
窗口视图可以按时间窗口聚合数据,并在窗口准备就绪时输出结果。它将部分聚合结果存储在一个内部或指定的表中,以减少延迟,并可以将处理结果推送到指定的表或使用WATCH查询推送通知。
创建窗口视图类似于创建物化视图。窗口视图需要一个内部存储引擎来存储中间数据。内部存储可以使用inner ENGINE子句指定,窗口视图将使用AggregatingMergeTree作为默认的内部引擎。
莫顿编码(Morton encoding)
也称为Z曲线(Z-order curve)或Z排序索引(Z-order indexing),是计算机科学中用于将多维数据映射到一维空间同时保持局部性的方法。这种技术在空间索引和图像处理中特别有用,它可以有效地存储和查询多维数据结构。
莫顿编码的工作原理是对坐标值的位进行交错。例如,如果你有两个维度的坐标(x, y),你将从最低有效位(LSB)开始交错x和y的位,形成一个单一的长整数,代表它们在Z曲线上的位置。过程如下:
- 将每个坐标转换为其二进制表示。
- 交错这些坐标的位,从最低有效位开始。
- 结果的交错位序列形成了该点的莫顿代码。
这里有一个例子,说明如何使用每个坐标4位的莫顿编码二维点(2, 3):
- 二进制表示:
- x = 2 -> 010 (在4位格式中,这变成0010)
- y = 3 -> 011 (在4位格式中,这变成0011)
- 交错位:
- 从最低有效位开始,我们从x和y中各取一位,然后将它们串联起来。
- 结果将是00001101,这是莫顿代码的二进制表示。
- 转换回十进制:
- 00001101的十进制值是13。
莫顿代码13现在代表了点(2, 3)在Z曲线上的位置。
莫顿编码的一个重要性质是,在原空间中彼此接近的点往往也有彼此接近的莫顿代码。这个性质帮助在数据映射到一维空间时保持局部性,使得范围查询和其他空间操作更容易进行。
在更高维度中,同样的原则适用;你只需交错更多的位序列。然而,随着维度的增加,莫顿编码的有效性会下降,这是因为维度诅咒(curse of dimensionality)。
莫顿编码在各种应用中使用,包括:
- 数据库中的空间索引。
- 纹理映射和图像处理。
- 光线追踪中的加速结构(例如,边界体积层次结构)。
莫顿编码的实现可在许多编程语言中找到,可以根据应用的具体需求优化性能。